𝓔𝓿𝓸Sem is a scientific project meant to explore the “Evolving Semantics” at play in the world's languages. It brings in one place the vast knowledge acquired by generations of scholars in the domain of etymology, for a variety of language families. Our purpose is to observe empirically the way languages have built semantic connections between concepts, through the historical evolution of their lexicons.
As of January 2026, 𝓔𝓿𝓸Sem features a total of 30,359 concepts, expressed by 260,022 words from 3,345 languages. These words descend from 29,664 etyma from 170 protolanguages.
-
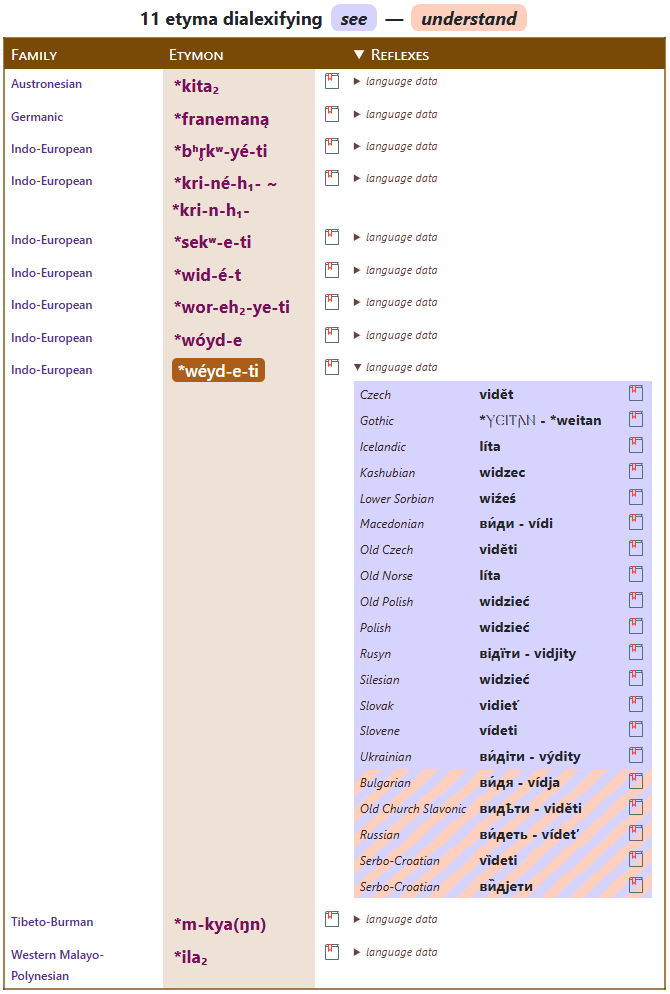
𝓔𝓿𝓸Sem builds around the notion of dialexification. It combines graphs with tables, to display the historical relations between concepts, across the world's families.
→ Read our online manual. -
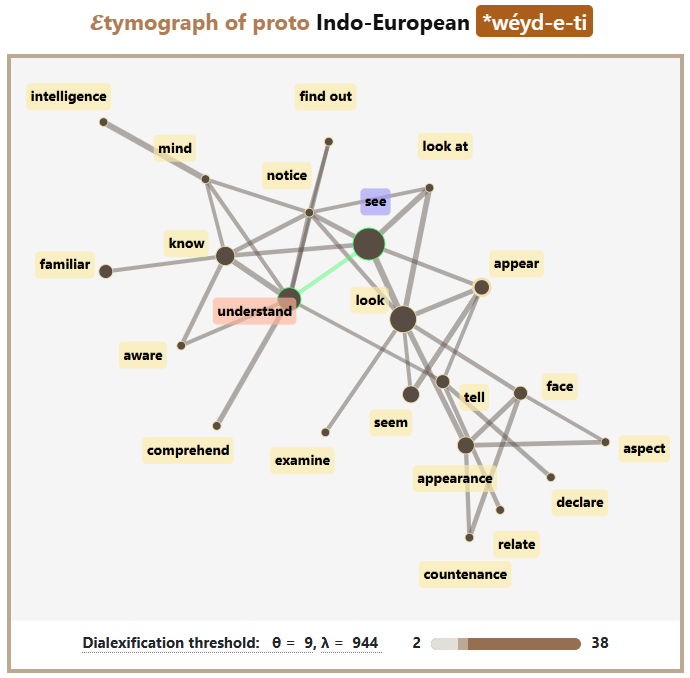
𝓔𝓿𝓸Sem visualizes the internal semantic diversity of each cognate set in the form of “𝓔tymographs”.
→ Explore our 𝓔tymographs. -
𝓔𝓿𝓸Sem analyzes the proximity, synchronic and diachronic, that language families establish among concepts.
→ Search 𝓔𝓿𝓸Concepts, our interactive catalogue of concepts, and filter etyma based on their dialexification patterns. -
Each of these data points can be retrieved through our search engine.
→ Use our 𝓔𝓿𝓸Search engine to filter the database by proto-languages, etyma, languages, words, and/or concepts. -
Thanks to the menu “𝓔𝓿𝓸Lists”, you can retrieve specific index pages for every language or proto-language represented on 𝓔𝓿𝓸Sem:
→ Search through the index of all languages, or the index of all proto-languages. -
𝓔𝓿𝓸Sem is being developed by a team of researchers and programmers based at CNRS—LaTTiCe (Paris)
→ Meet our team.
Here is how you can cite the 𝓔𝓿𝓸Sem database:
Alexandre François, Mathieu Dehouck, Konstantin Henke & Siva Kalyan. () 𝓔𝓿𝓸Sem: A database of dialexification across language families. Online database. Lattice & HéLiCéO, CNRS — ENS‒PSL, Paris. https://tiny.cc/EvoSem [access date: ]
If you wish to know more about 𝓔𝓿𝓸Sem — why and how it was created, or how to read its graphs and tables — you can read our paper:
Mathieu Dehouck, Alexandre François, Siva Kalyan, Martial Pastor & David Kletz. (2023)𝓔𝓿𝓸Sem: A database of polysemous cognate sets. In Nina Tahmasebi et al. (conv.), Proceedings of the 4th Workshop on Computational Approaches to Historical Language Change, 66–75. Singapore. Association for Computational Linguistics.
Download area
The data underlying 𝓔𝓿𝓸Sem can be downloaded from this zipped folder: